昨天我們把 Seq2Seq 搭配 Attention 的模型結構完整實作出來,而今天的重點就放在訓練與應用,讓它能處理基本的中英翻譯。那問題來了怎麼判斷這些翻譯結果到底好不好?我們會先聊各種量化生成品質的方法,接著還會討論生成策略這個關鍵主題,並用實際翻譯範例對照,看看不同策略會讓輸出產生哪些差異。
當我們在訓練深度學習模型時,特別是在處理高準確度的任務時,一個常見卻經常被忽略的問題就是隨機性帶來的結果波動。簡單來說如果我們今天用同樣的資料、同樣的模型、甚至同樣的訓練設定重跑一次,卻得到了不一樣的結果,這就讓我們很難判斷模型的實際效能。這時固定隨機亂數種子就派上用場了。
在深度學習中有許多環節會用到隨機性,例如:初始化權重、資料打亂(shuffling)、Dropout 機制等,這些隨機因素會導致每次訓練時模型的行為略有不同。為了確保結果具有可重現性(reproducibility),我們通常會在程式的一開始就鎖定這些亂數來源,讓訓練的每一步都能夠照著一樣的隨機路徑走,這對於實驗的比較與調參工作極為重要,而程式碼我們可以如此撰寫。
import torch
import numpy as np
import random
def set_seeds(seed):
random.seed(seed) # 設定 Python 標準庫的亂數生成器種子
np.random.seed(seed) # 設定 NumPy 亂數生成器種子
torch.manual_seed(seed) # 設定 PyTorch 的 CPU 亂數生成器種子
if torch.cuda.is_available():
torch.cuda.manual_seed(seed) # 設定 PyTorch 在單個 GPU 上的亂數種子
torch.cuda.manual_seed_all(seed) # 設定 PyTorch 在所有 GPU 上的亂數種子
torch.backends.cudnn.benchmark = False # 禁用 cuDNN 的基準測試功能
torch.backends.cudnn.deterministic = True # 強制 cuDNN 使用確定性算法
set_seeds(2526)
而在這程式中特別要注意的是最後兩行 torch.backends.cudnn 的設定,這是在使用 GPU 訓練時的一個小技巧。因為 cuDNN 在預設情況下會自動尋找最佳化的算法來加速運算,但這種最佳化有時候是非確定性的,也會造成結果的不同,因此我們關閉這個功能改用比較穩定、可重現的算法。
我已經先把中英文對照的資料整理好,存在 translate.csv 這個檔案裡。用 Pandas 讀進來之後,我們就能很快把這些資料轉成好操作的格式:
import pandas as pd
df = pd.read_csv('translate.csv')
input_texts = df['chinese'].values
target_texts = df['english'].values
這邊的 input_texts 裡面放的是中文原文,而 target_texts 則是對應的英文翻譯。這種格式對於訓練像 Transformer 這類的 Seq2Seq 模型來說非常實用。
在翻譯任務中,我們會需要兩個不同的 Tokenizer,分別處理中英文。這時就可以用 Hugging Face 提供的 AutoTokenizer,像下面這樣:
from transformers import AutoTokenizer
def process_texts(tokenizer, texts):
ids = tokenizer(texts[20]).input_ids
return tokenizer.decode(ids)
src_tokenizer = AutoTokenizer.from_pretrained('bert-base-chinese')
tgt_tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased', use_fast=False)
cn_text = process_texts(src_tokenizer, input_texts)
en_text = process_texts(tgt_tokenizer, target_texts)
print('中文轉換後的結果:', cn_text, '\n英文轉換後的結果:', en_text)
輸出看起來像這樣:
中文轉換後的結果: [CLS] 我 沒 事 。 [SEP]
英文轉換後的結果: [CLS] i'm ok. [SEP]
可以看到,Tokenizer 已經自動幫我們把 BERT 所需的特殊符號 [CLS] 跟 [SEP] 加上去了,這對於後面模型的輸入格式來說是很關鍵的。
當我們準備好中英文對照資料,要拿來訓練模型之前,會先自己寫一個叫做 TranslateDataset 的類別,幫助我們處理像是 Tokenizer 還有把資料打包成 batch 這些步驟。
from torch.utils.data import Dataset, DataLoader
from sklearn.model_selection import train_test_split
class TranslateDataset(Dataset):
def __init__(self, x, y, src_tokenizer, tgt_tokenizer):
self.x = x
self.y = y
self.src_tokenizer = src_tokenizer
self.tgt_tokenizer = tgt_tokenizer
def __getitem__(self, index):
return self.x[index], self.y[index]
def __len__(self):
return len(self.x)
def collate_fn(self, batch):
batch_x, batch_y = zip(*batch)
src_tokens = self.src_tokenizer(
list(batch_x),
max_length=256,
truncation=True,
padding="longest",
return_tensors='pt'
)
tgt_tokens = self.tgt_tokenizer(
list(batch_y),
max_length=256,
truncation=True,
padding="longest",
return_tensors='pt'
)
return {
'input_ids': src_tokens.input_ids,
'labels': tgt_tokens.input_ids
}
x_train, x_valid, y_train, y_valid = train_test_split(
input_texts,
target_texts,
train_size=0.8,
random_state=46,
shuffle=True
)
trainset = TranslateDataset(x_train, y_train, src_tokenizer, tgt_tokenizer)
validset = TranslateDataset(x_valid, y_valid, src_tokenizer, tgt_tokenizer)
train_loader = DataLoader(
trainset,
batch_size=64,
shuffle=True,
num_workers=0,
pin_memory=True,
collate_fn=trainset.collate_fn
)
valid_loader = DataLoader(
validset,
batch_size=64,
shuffle=True,
num_workers=0,
pin_memory=True,
collate_fn=validset.collate_fn
)
不過在正式開始之前,有一個超級關鍵的地方一定要注意,我們在用 train_test_split 把資料分成訓練集和驗證集的時候,一定要記得把 shuffle 設成 True!這點為什麼這麼重要呢?因為我們的資料原本是照句子長度排好的從短的排到長的。如果你沒有打亂順序直接切一刀,那訓練集可能就全是短句,驗證集就會變成一堆長句。
這樣一來問題就大了模型在訓練階段只看過簡單的短句,根本沒機會學習怎麼處理比較長的句子。等到驗證階段突然丟給它一堆沒見過的長句,它當然會表現得很爛。
在這裡我們使用昨天已經準備好的 LSTM Encoder、Decoder 還有 Attention 模組,來組成一個完整的 Attention-based Seq2Seq 模型。我們把這個包成一個 Attentionseq2seq 類別。
class Attentionseq2seq(nn.Module):
def __init__(
self,
src_vocab_size: int,
tgt_vocab_size: int,
hidden_size: int,
src_pad_idx: int,
tgt_pad_idx: int,
bos_token_id: int,
eos_token_id: int,
max_decode_len: int = 128
):
super().__init__()
self.encoder = EncoderLSTM(src_vocab_size, hidden_size, src_pad_idx)
self.attn = BahdanauAttention(hidden_size)
self.decoder = DecoderLSTM(self.attn, hidden_size, tgt_vocab_size, tgt_pad_idx)
self.bos_id = bos_token_id
self.eos_id = eos_token_id
self.max_decode_len = max_decode_len
# 用 CrossEntropyLoss 直接吃 raw logits
self.criterion = nn.CrossEntropyLoss(ignore_index=tgt_pad_idx)
self.src_pad_idx = src_pad_idx
self.tgt_pad_idx = tgt_pad_idx
在模型的前向傳遞過程中,主要分為幾個關鍵步驟。首先輸入的句子會被送進 Encoder,透過其處理後得到對應的輸出(enc_out)以及最後的隱藏狀態(h, c)。接著會根據輸入的 padding 資訊建立 source mask,這是為了讓後續的Attention能夠忽略掉那些不應參與計算的 padding 位置。
進入 Decoder 階段後,模型會從起始標記 <BOS> 開始,逐步產生目標句子中的每個詞。這裡會用到 teacher forcing 技術,也就是在每一步決定是用 Ground truth 作為下一步的輸入,還是用模型自己預測出來的詞。這個選擇是透過機率來控制的。
def forward(self, src_ids, tgt_ids, teacher_forcing_ratio: float = 1.0):
device = src_ids.device
enc_out, (h, c) = self.encoder(src_ids) # enc_out: (B, T, H)
src_mask = (src_ids != self.src_pad_idx) # (B, T), True=valid
T = tgt_ids.size(1)
logits_steps = []
cur = tgt_ids[:, 0:1] # BOS
for t in range(1, T):
step_logits, (h, c) = self.decoder(enc_out, (h, c), cur, src_mask)
logits_steps.append(step_logits)
# 每 step 的隨機 teacher forcing
use_tf = torch.rand((), device=device) < teacher_forcing_ratio
next_in = tgt_ids[:, t:t+1]
pred = step_logits.argmax(-1)
cur = next_in if use_tf else pred
logits = torch.cat(logits_steps, dim=1) # (B, T-1, V)
target = tgt_ids[:, 1:]
loss = self.criterion(
logits.reshape(-1, logits.size(-1)),
target.reshape(-1)
)
return loss, logits
在訓練階段,我們會把每個時間步驟模型輸出的 logit 都收集起來,然後跟對應的正確目標詞比對,用 CrossEntropyLoss 來計算整體的損失。這部分沒什麼懸念。
但到了生成階段情況就不一樣了,我們不再依賴 ground truth也就是說模型得靠自己一步一步地生出接下來的詞,這就是所謂的自回歸(autoregressive)生成過程。
@torch.no_grad()
def generate(self, input_ids, max_len=50):
self.eval()
batch_size = input_ids.size(0)
# Encoder
encoder_outputs, decoder_hidden = self.encoder(input_ids)
src_mask = (input_ids != self.src_pad_idx) # (B, T_src)
# 初始化 decoder 輸入為 BOS
decoder_input = torch.full(
(batch_size, 1),
self.bos_id,
dtype=torch.long,
device=input_ids.device
)
generated_ids = []
finished = torch.zeros(batch_size, dtype=torch.bool, device=input_ids.device)
for _ in range(max_len):
# decoder: (B,1,V)
step_logits, decoder_hidden = self.decoder(
encoder_outputs, decoder_hidden, decoder_input, src_mask
)
# 直接 argmax 拿下一個 token
next_token = step_logits.argmax(dim=-1) # (B,1)
# 對已完成序列固定輸出 EOS
next_token = next_token.masked_fill(finished.unsqueeze(1), self.eos_id)
generated_ids.append(next_token)
decoder_input = next_token
finished |= next_token.eq(self.eos_id).squeeze(1)
if finished.all():
break
generated_ids = torch.cat(generated_ids, dim=1) # (B, L)
return generated_ids
Decoder 的輸入一開始是 <BOS>,然後每次迭代都把上一步產生的 token 當成下一步的輸入,這就是模型在自己跟自己對話的過程。模型每步會輸出 logits,我們直接對它做 argmax,挑出最有機會的下一個 token。要注意的是,如果某個樣本已經產生了 <EOS>,那後面的步驟就會固定讓它繼續產生 <EOS>,這是透過 masked_fill 這一行達成的。
為了追蹤哪些句子已經結束,我們用一個 finished 的布林張量記錄每個樣本的狀態。只要全部樣本都完成了,我們就可以提早跳出回圈,省一點計算資源。最後把每一輪產生的 token 串起來,組成完整的輸出序列,這就是模型最終生成的結果。
我們在每個時間步都直接用 argmax 選出機率最大的那個 token,這種做法就叫做 Greedy Decode。它的意思很簡單每一步都貪婪地挑目前看起來最有可能的選項,完全不回頭、也不考慮全局最優。雖然簡單快速,但有可能錯過更好的整體序列。
最後我們就可以實際把模型建起來了,這裡比較特別的地方是,我們直接把 tokenizer 裡的特殊符號拿來當成生成任務的起點和終點:也就是把 CLS 當作 <BOS>,SEP 當作 <EOS>。雖然這些符號原本不是設計來這樣用的,但它們在語意上其實也挺接近,實務上也很常這樣處理。
model = Attentionseq2seq(
src_vocab_size=len(src_tokenizer),
tgt_vocab_size=len(tgt_tokenizer),
hidden_size=512,
src_pad_idx=src_tokenizer.pad_token_id,
tgt_pad_idx=tgt_tokenizer.pad_token_id,
bos_token_id=tgt_tokenizer.cls_token_id, # 目標 BOS
eos_token_id=tgt_tokenizer.sep_token_id, # 目標 EOS
max_decode_len=128
)
其他設定就比較直觀了我們把來源和目標語言的 vocabulary 長度、padding token 的位置,以及最大生成長度這些資訊都傳進模型裡,讓它能正確處理序列的開始、中止、以及忽略不重要的 padding 區塊。
有了模型之後,接下來就是進入訓練階段啦。這裡我們使用 AdamW 這個優化器來更新模型參數,學習率設成 1e-3。設定上同樣沒有太多華麗的花招但該考慮的都有顧到:我們讓訓練最多跑 100 個 epoch,每一輪都會經過訓練集和驗證集的評估;同時設置了 early stopping 的機制,若模型在驗證集上的表現連續五輪沒有進步,就會自動停下來,避免過擬合或多餘的運算。而這次還加入了 grad_clip=1.0 來限制梯度的最大值,這可以防止訓練過程中出現梯度爆炸的情況。
from trainer import Trainer
import torch.optim as optim
optimizer = optim.AdamW(model.parameters(), lr=1e-3)
trainer = Trainer(
epochs=100,
train_loader=train_loader,
valid_loader=valid_loader,
model=model,
optimizer=optimizer,
early_stopping=5,
load_best_model=True,
grad_clip=1.0,
)
trainer.train(show_loss=True)
輸出結果:
Train Epoch 10: 100%|██████████| 374/374 [00:26<00:00, 13.86it/s, loss=0.330]
Valid Epoch 10: 100%|██████████| 94/94 [00:03<00:00, 29.75it/s, loss=1.707]
Train Loss: 0.30791 | Valid Loss: 2.14102 | Best Loss: 2.06168
Train Epoch 11: 100%|██████████| 374/374 [00:26<00:00, 13.91it/s, loss=0.275]
Valid Epoch 11: 100%|██████████| 94/94 [00:03<00:00, 30.11it/s, loss=2.064]
Train Loss: 0.25543 | Valid Loss: 2.14524 | Best Loss: 2.06168
--------------------------------------
| Model can't improve, stop training |
--------------------------------------
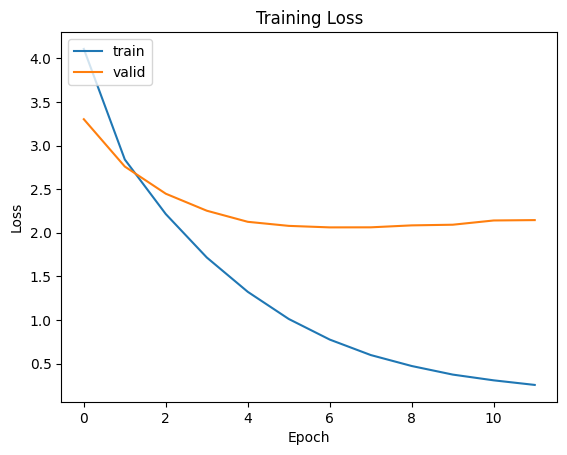
從圖中可以看出,train loss 隨著 epoch 增加穩定下降,表示模型對訓練資料的學習效果不斷提升;但相對地,valid loss 則是在前幾個 epoch 有所下降後便趨於平緩甚至略有上升,最後大致停留在 2.1 附近。
這種現象代表模型雖然學會了訓練資料的特徵,但泛化能力卻沒有同步跟上是典型的Overfitting。這些原因有可能是模型容量過大,相對於資料規模來說太複雜,而這裡其實最有可能的是資料本身的多樣性不足,使得模型很快就掌握了可泛化的部分。
為了解決這個問題我可以試著加一些正規化的方法,讓模型不要太記得訓練資料的細節,也可以用資料增強來讓樣本看起來更有變化或是直接把模型縮小一點。甚至也可以用AI產生一些新的資料,混進去再重新訓練看看。
當你訓練好一個翻譯模型後,第一個冒出來的問題大概就是:「它翻得好嗎?」這時,BLEU 分數(Bilingual Evaluation Understudy) 就是一個常見又方便的自動評估指標,能快速幫你判斷模型在測試資料上的表現。這裡我們會用 sacrebleu 套件來幫忙計算:
import torch
import sacrebleu
def translate_and_eval(model, tokenizer, loader):
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model.to(device).eval()
hyps, refs = [], []
with torch.no_grad():
for batch in loader:
batch = {k:v.to(device) for k,v in batch.items()}
out = model.generate(input_ids=batch['src_ids'])
hyps += tokenizer.batch_decode(out, skip_special_tokens=True)
refs += tokenizer.batch_decode(batch['tgt_ids'], skip_special_tokens=True)
bleu = sacrebleu.corpus_bleu(hyps, [refs], lowercase=True)
print(f"Corpus BLEU: {bleu.score:.2f}")
translate_and_eval(model, tgt_tokenizer, valid_loader)
輸出結果會長這樣:
Corpus BLEU: 23.23
從這個分數來看,模型的翻譯表現已經有一定水準。雖然還談不上可以直接應用在真實場景,但至少比亂猜好得多了。而且這次訓練資料其實不多,還能拿到這樣的 BLEU 分數,說真的已經是個不錯的起步點了。
我們花了大約兩個禮拜的時間,一步步介紹過去那些經典的模型架構。今天終於實作了基於 LSTM 的 Seq2Seq 模型,還加上了 Attention 機制。老實說,這套架構雖然經典又實用,但現在已經慢慢不那麼流行了。原因很簡單當資料量一大、模型一複雜,LSTM 的訓練效率就會變得很差。
這是因為它的運算方式只能一個步驟接著一個步驟來,沒辦法平行處理,每個時間點都得等前一個跑完。這樣的特性對 GPU 來說很不友善,訓練速度也自然受限。
所以從接下來的章節開始,我們就要正式進入 Transformer 的世界了。會從它的核心架構講起,一步步帶大家拆解 Self-Attention 的原理和實作,並說明它為什麼這麼快、這麼受歡迎。下一站我們就從 Attention 前進到 Self-Attention,從線性序列的處理邏輯,跨進一口氣可以同時處理整個矩陣的世界!


 iThome鐵人賽
iThome鐵人賽